The Insatiable Hunger for Compute: Powering Large Language Models
Introduction
In this day and age, language models are ubiquitous. We constantly interact with them even without knowing. For example, applications such as, next word predictions while typing on our smartphone keyboard, suggestions while writing an email, or simply converting text-to-speech, use language models in some form or the other. Furthermore, new research is constantly being published at an unprecedented rate. But recently, these language models are getting big, and are now being referred to as Large Language Models or LLMs.
The size of these LLMs are in the order of billions (number of parameters) and keeps growing larger. They also require colossal datasets as training datasets, to produce meaningful results. In fact, one of the most used LLM nowadays, ChatGPT, was trained on approximately 570GB of data (which is surprisingly not large at all!) [2]. Given that the Internet has existed for a few decades now, it is not difficult to find data of such scale. The point to highlight here is the sheer size of such LLMs. The ChatGPT model is based on InstructGPT [3], and has around 175 Billion parameters! This large number of parameters allows the model to learn complex underlying characteristics of the data and results in a system (model) to have a good understanding of the data, but let's pause for a moment and think of the compute required to achieve such good performance 🤔.
How much compute is required?
The amount of compute required to train these models is significant. Let's look at a few examples of LLMs and their respective compute requirements. The first model is a (relatively) small model called GPT-NeoX-20B [4], which has 20 Billion parameters. It required 96 40GB Nvidia A100 GPUs for training. A more recent model LLaMA2 [5] has around 70 Billion parameters and required 2000 80 GB Nvidia A100 GPUs for training. Another model called BLOOM [6] has close to 176 Billion parameters and required over 100 days to train using 384 80GB Nvidia A100 GPUs. Surely, using these many GPUs uses a lot of electricity and power, and as models get bigger or if we need to train them for longer to achieve the desired performance, the power consumption increases further.
If it were the case that language models are released every few months of so, then this hunger for GPUs could be satisfied fairly quickly and the power consumptions could have been kept in check. But this isn't the case. Take a look at the figure below, which shows the cumulative number of arxiv papers on language models published over the years (for the query term "Language Model" and "Large Language Model", Figure taken from [1]).

This means that as more language models are trained, the more compute resources are being used, leading to an ever growing need for electricity to run these computational resources. Is this something to be concerned about?
A simple comparison to daily life
Given the times we live in, it is important to recognize the impact of the increasing power consumption on climate. Let's take the example of the BLOOM model that we talked about before. This 176 Billion parameter is estimated to have consumed around 433 MWh (Mega Watt hours) cumulatively during the training procedure (See the Figure below for more statistics - taken from [7]). Moreover, it is estimated that the carbon emissions are approximately 25-30 tonnes of CO2 equivalent [7] during training. These numbers are certainly not something to be overlooked. For reference, 1 MW (Mega Watt) of can power between 400-1000 homes in a year. So definitely, this is something to pay attention to.
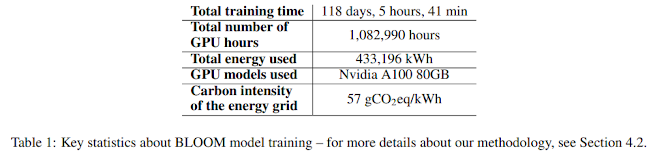 |
| Figure taken from the paper estimating carbon footprint of the BLOOM model [7]. |
But one might say, "We need these big model to provide us with the best results!". Certainly! And as we saw before, this increase in model size has come with the advantages of improved performance on NLP tasks, improved understanding of language in general, and emergent capabilities too! But we can definitely do more to address the challenges above that come with training LLMs.
Recently, big companies such as Meta participate in sustainability programs in order to offset the emitted carbon during the development of LLMs. This is a right step towards addressing the issues above, but can we do more?
Possible solutions to tackle such challenges
A method worth investigating?
Given my fascination with the human brain 🧠, I recently started investigating model learning techniques inspired by the human mind. One of such techniques is known as Curriculum Learning [9]. Although, there will be a more detailed post on this later, the general idea of curriculum learning is to train the model (LLM) by showing it examples in an order of increasing difficulty. The idea is to follow the notion of how humans and animals learn complex concepts - first learn about the easy examples, and then move on to the difficult samples. Numerous works have shown that this method of training leads to improved performance on natural language understanding tasks. Furthermore, curriculum learning also has been shown to decrease convergence time of models, which means that fewer computational resources are used leading to less electricity consumption.
Okay, so why doesn't everyone use this method? One of key challenges of curriculum learning is the actual task of designing the curriculum itself. Generally, this is highly task specific and there is no one solution fits all. In fact, it is highly likely that designing the task specific curriculum itself will lead to more electricity consumption compared to training an LLM without curriculum learning. This will lead to the original premise of reducing electricity consumption falling apart. In addition, as datasets get larger, it gets even more complex to design a sophisticated curriculum. That being said, as more research is carried out in the domain of clever training strategies, such as curriculum learning, higher is the possibility of inventing new ways to more efficiently train LLMs.
In another post, we will see some specifics of curriculum learning and how it has improved language model performance in many NLP tasks!
NOTE: The blog has been moved to substack for a better user experience. Further posts will be published on substack. https://rohansaha60.substack.com/
Comments
Post a Comment